
Cloud Native Platform Engineering in 2026, From Kubernetes v1.36 to Compliance by Design

Cloud native platforms are entering a new stage of maturity.
A few years ago, the conversation was mostly about getting workloads into containers. Today, the real challenge is different, how do we build a platform that is secure by design, observable by design, cost-aware by design, and ready for audit without slowing engineering teams down?
That is where Kubernetes v1.36, Infrastructure-as-Code, ingress design, secrets management, and DevOps compliance all start to connect.
This is no longer just a cluster conversation. It is a platform operating model.
The platform view
A production-grade platform should not start with application manifests. It should start with the foundation, cloud accounts, networks, identity, encryption, cluster boundaries, logging, and policy.
The application team should consume a paved road. The platform team should define the road.
The important point is that application deployment is only one layer. The platform has to provide identity, security, release controls, observability, recovery, and evidence.
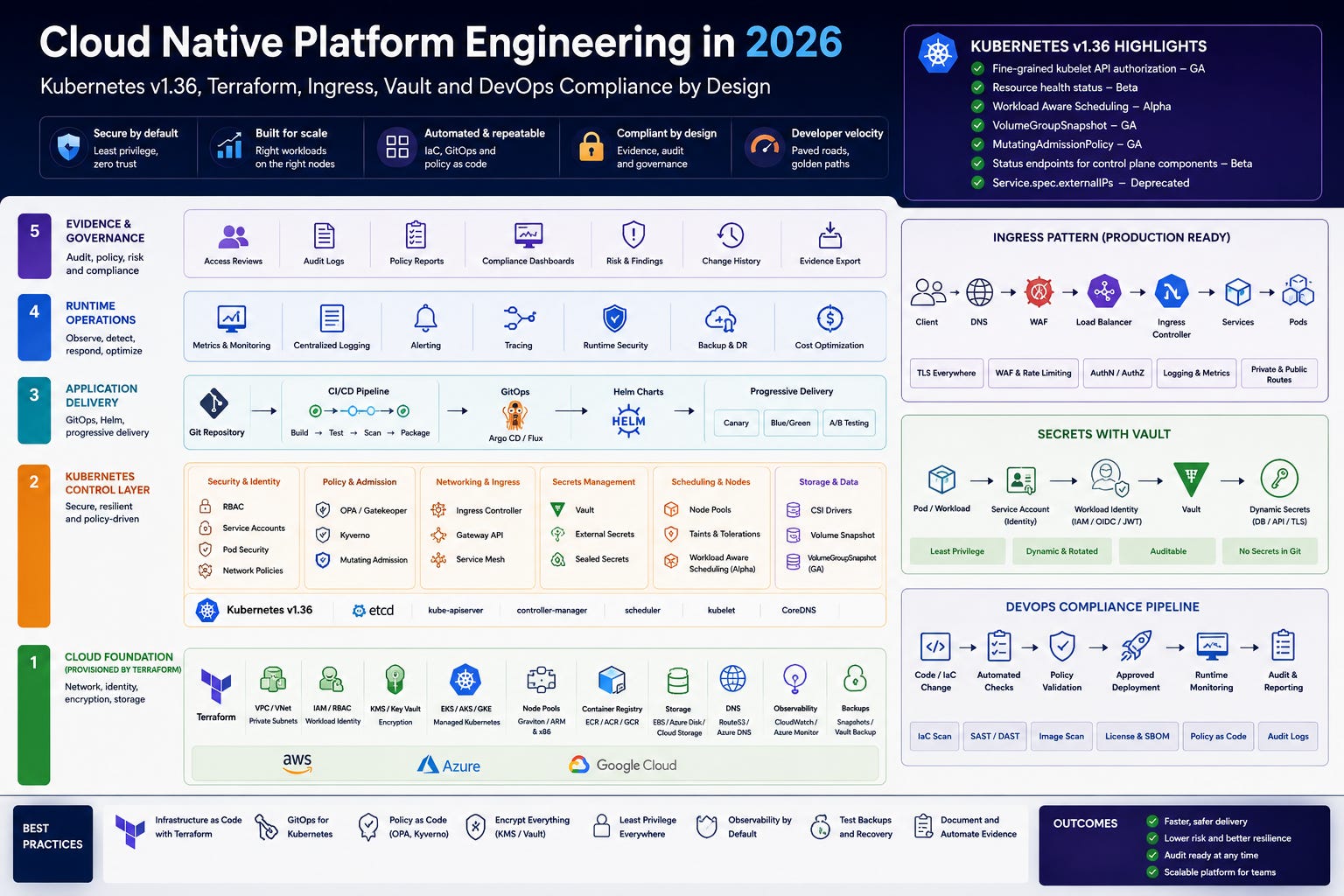
What Kubernetes v1.36 changes for platform teams
Kubernetes v1.36 is not just another incremental release. It pushes several areas that matter directly to platform engineering.
Fine-grained kubelet API authorisation is now stable. This matters because monitoring and operational tooling should not need broad node proxy permissions just to inspect node-level information. It supports the principle of least privilege at a level that is often overlooked, the node interface.
Resource health status moves further forward as well. For platforms running GPU, accelerator, or specialised hardware workloads, being able to understand whether a pod is failing because of unhealthy allocated resources is a practical operations improvement. This is especially relevant for AI, ML, high-performance computing, and batch processing platforms.
Workload Aware Scheduling enters as an alpha capability. The direction is important, instead of treating every pod as an isolated unit, the scheduler can start reasoning about related workloads as a group. That matters for distributed jobs where partial placement is wasteful or even useless.
Storage also gets important attention. Volume group snapshots reaching GA is a big deal for stateful workloads because it allows crash-consistent snapshots across multiple persistent volumes. Mutable CSI node allocatable information also improves scheduling accuracy because the scheduler can make decisions using fresher storage capacity data.
For platform teams, the message is clear, cluster design needs to be workload-aware, security-aware, and evidence-aware.
Provision the cloud platform before deploying the cluster
A common mistake is to create the cluster first and fix the platform later.
That usually leads to public endpoints, over-permissive IAM, weak network separation, missing logs, unclear ownership, and Terraform state that contains more sensitive information than expected.
A better model is to provision the foundation first.
Terraform should own the cloud platform layer. That includes the network, private subnets, route tables, NAT or firewall paths, KMS keys, IAM roles, workload identity, container registries, DNS, storage classes, log destinations, and backup resources.
For AWS, this might mean EKS with private node groups, IAM Roles for Service Accounts, KMS-backed encryption, Graviton node pools for suitable workloads, and VPC endpoints for ECR, S3, STS, CloudWatch, and Secrets Manager.
For Azure, the same principle applies with AKS, managed identities, private clusters, Azure Key Vault, private endpoints, Azure Monitor, and policy integration.
The cloud provider changes, but the platform pattern stays consistent.
The reason Terraform belongs at the foundation layer is that infrastructure needs lifecycle control. You need a plan, approval, apply, drift detection, state protection, and a clear history of who changed what.
But secrets should be handled carefully. Sensitive values should not be casually passed through variables, outputs, Helm values, or CI logs. Terraform state should be treated as sensitive data, encrypted, access-controlled, and excluded from normal source control workflows.
Ingress is not just routing
Ingress design is one of the most important platform decisions because it defines how external traffic enters the system.
At minimum, the platform should standardise public versus private routes, TLS termination, certificate rotation, WAF integration, authentication patterns, rate limiting, request size limits, and logging.
A simple production ingress pattern looks like this.
The mistake is to allow every team to expose services differently. One team uses a public LoadBalancer, another uses an ingress object, another exposes NodePort, and another bypasses the standard WAF path entirely.
That creates operational inconsistency and audit complexity.
A platform team should provide approved exposure patterns. For example, public APIs go through WAF and managed TLS. Internal services use private ingress or service mesh routing. Admin endpoints are private by default. Metrics and debug endpoints are never public.
Kubernetes v1.36 also makes the deprecation of Service.spec.externalIPs worth paying attention to. If a platform still relies on that field, it should be reviewed and migrated to safer patterns such as cloud-managed load balancers, Gateway API, or controlled private routing.
Scheduling is now a platform concern
Scheduling is often treated as something the cluster just does automatically.
That works until workloads become more complex.
Once you introduce batch processing, AI/ML jobs, GPUs, spot capacity, ARM nodes, Graviton node pools, compliance-sensitive workloads, and strict availability requirements, scheduling becomes a platform design area.
A mature platform should define node pools by workload class.
Then you use labels, taints, tolerations, topology spread constraints, resource requests, priority classes, and autoscaling rules to keep workloads in the right place.
The platform should prevent accidental placement. A PCI workload should not land on a general-purpose node pool because someone forgot a node selector. A GPU workload should not block business-critical APIs. A batch job should not starve low-latency services.
The v1.36 movement around workload-aware scheduling reinforces this direction. Platforms need to understand workload groups, not only individual pods.
Secrets management, Vault and workload identity
Secrets are where many cloud native platforms become fragile.
The wrong pattern is to put secrets directly into Helm values, Terraform variables, CI environment variables, or Kubernetes Secret manifests stored in Git.
A stronger pattern is to use workload identity and an external secret manager. Vault is a good fit where you need centralised secret policy, dynamic credentials, rotation, leasing, and detailed audit trails.
The application should receive only what it needs, for as long as it needs it. Support engineers should not automatically inherit access to production secrets just because they can view workloads.
Vault becomes more powerful when its policies are mapped to namespace, service account, environment, and application ownership. The goal is not just secret storage. The goal is controlled access with rotation and evidence.
DevOps compliance must be built into the pipeline
Compliance should not be a spreadsheet exercise performed two weeks before an audit.
For SOC 2, ISO 27001, and PCI DSS, the strongest DevOps compliance model is evidence by design. Every control should produce evidence naturally as part of normal engineering work.
The platform should collect evidence for access reviews, change approvals, image scans, vulnerability exceptions, backup tests, incident response, encryption, logging, and production access.
If a support engineer restarts a production pod, there should be a ticket, a role assumption event, an audit log entry, and a Kubernetes event.
If a new service is exposed publicly, there should be a reviewed change, approved ingress path, TLS configuration, WAF coverage, and log destination.
If a secret is rotated, there should be a record of the rotation and proof that the consuming workload reloaded it safely.
That is what compliance by design looks like.
A practical platform blueprint
A strong cloud native platform can be organised into five layers.
Each layer should have a clear owner.
Cloud foundation is usually owned by the platform or infrastructure team. The Kubernetes control layer is owned by the platform team. Application delivery is shared between platform and engineering teams. Runtime operations are shared between SRE, DevOps, and support teams. Evidence and governance are shared with security, risk, and compliance teams.
This structure helps avoid one of the biggest problems in cloud native environments, unclear ownership.
What good looks like
A good platform should make the secure path the easiest path.
Developers should not need to understand every detail of RBAC, network policies, KMS, ingress controllers, pod security, service accounts, or backup configuration just to ship a service.
They should consume approved templates and golden paths.
The platform should enforce the non-negotiables.
That means private-by-default networking, least-privilege access, encrypted storage, controlled ingress, externalised secrets, image scanning, runtime monitoring, audit logging, and tested recovery.
It also means platforms should be designed for scaling from the beginning. Not just scaling pods, but scaling teams, environments, clusters, controls, and evidence.
Final
Cloud native maturity is not measured by how many clusters you run.
It is measured by how consistently you can provision, secure, observe, recover, and audit your platforms.
Kubernetes v1.36 gives platform teams more tools for security, scheduling, storage, and operational visibility.
Terraform gives teams a repeatable way to provision the cloud foundation.
Vault helps centralise and audit sensitive access.
Ingress patterns define how traffic safely reaches applications.
DevOps compliance connects all of this into an operating model that can stand up to real enterprise scrutiny.
The future of platform engineering is not just automation.
It is automation with guardrails, evidence, and trust.